
AMD vs. Intel: Which CPU is best suited to AI and Deep Learning?
Updated March 2024
When it comes to processors for Artificial Intelligence (AI) and Deep learning (DL), your two main options are AMD and Intel.
It can be hard to know which to choose, so this blog will focus on the fundamentals of each processor to help you decide which will be more beneficial to your AI/DL project.

Latest releases
For your reference, the latest releases from each brand are the Threadripper™ PRO 5000 series from AMD, and the 4th Generation Xeon® W 3-9 Series Processors from Intel, designed specifically to compete with the Threadrippers™. It has also been rumoured that the Threadripper™ PRO 7000 WX-Series will be coming very soon.
Price
Budget is a big concern, particularly for R&D departments.
Each series offers processors at different price points, so the good news is you’ll probably find a CPU in your price range, even if performance takes a hit.
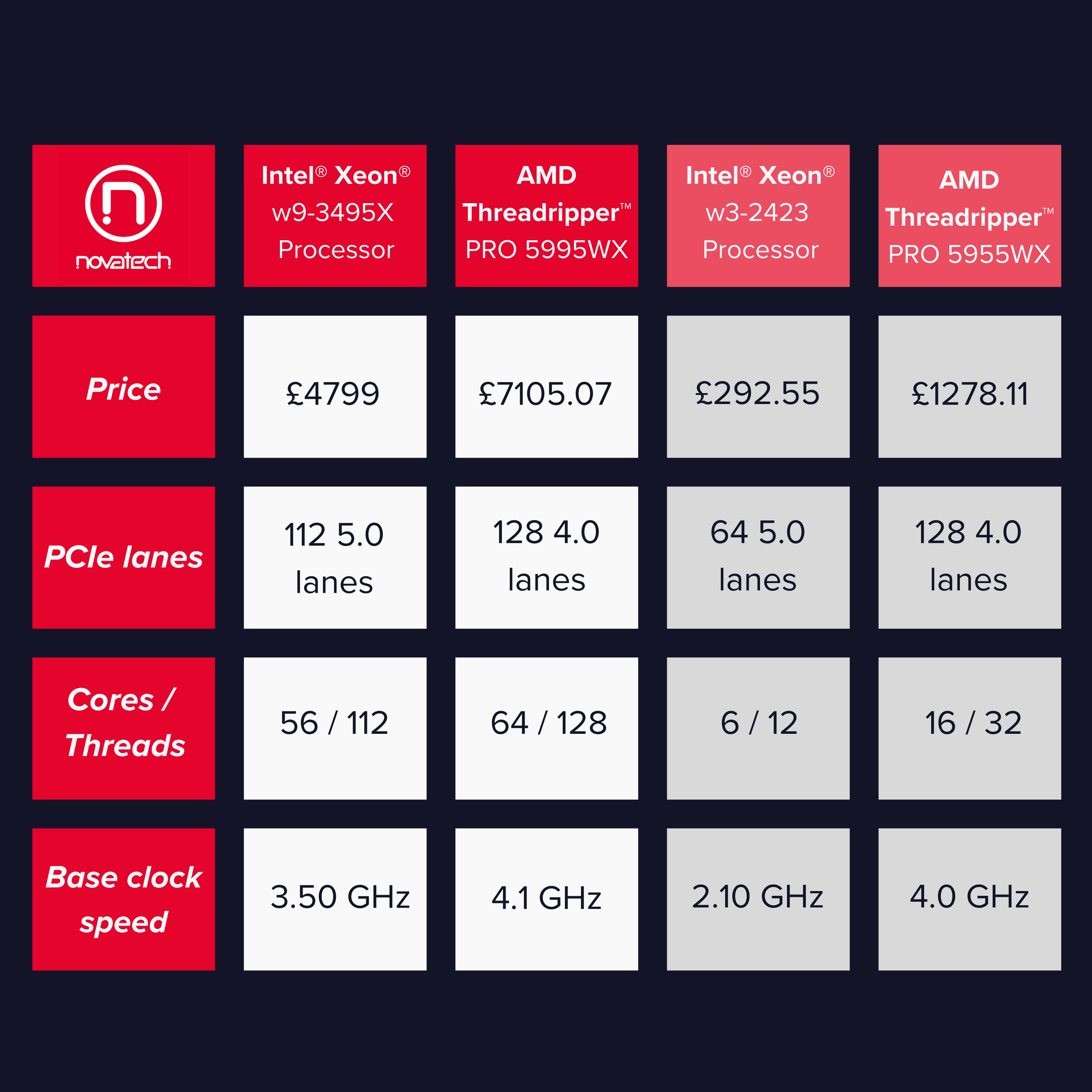
Intel’s most expensive Xeon® W processor comes in at a recommended £4799.00, and its most affordable at £292.55. AMD’s Threadripper™ Series can run from £7,105.07 to £1278,11.
The higher the specifications, the more expensive the processor will be. As a result, AMD’s higher performance is reflected in its more expensive prices.
Performance
Deep Learning workstations require PCIe bandwidth, so you should pay attention to how many PCIe lanes a CPU has. The lanes on your CPU are necessary for high-speed storage, which is vital in AI training. They are also primarily assigned to your graphics card (GPU), with each graphics card requiring 16 (known as x16) to run at 'full speed'.
GPUs still do most of the heavy lifting within AI/DL workloads, and to run multiple simultaneously, DL workstations generally require a CPU with at least 40 PCIe lanes. Only the three series mentioned can provide this number of lanes, with AMD’s Ryzen™ and Intel’s Core ® ranges only offering 16-20.
Intel's latest Xeon® W Processors offer up to 112 Gen 5.0 lanes. AMD top this with up to 128 4.0 lanes from their Threadripper™ PRO 5000 WX-Series Processors.
Junior Solutions Architect, Alex, talks AMD vs Intel for AI and Deep Learning Workloads.
Cores and Threads
AI and DL workloads require enough cores to pre-process datasets and multithreaded workloads.
AMD’s latest Threadripper™ range offers up to 64 cores and 128 threads. In contrast, Intel’s latest Xeon® W Processors offer up to 56 cores with 112 threads.
Clock speed
Clock speed can be equally as important as the number of cores with AI/DL workloads. For example. when calculations must be completed sequentially, for example, a CPU with less cores and a higher frequency will perform better.
Intel’s latest Xeon® series offers base frequencies of up to 3.50 GHz, whereas AMD’s Threadripper™ series offers 4.1 GHz.
With sufficient cooling, all Threadripper™ processors can provide max speeds of up to 4.5 GHz, with Intel’s Xeon’s reaching up to 4.80 GHz.
We hope that this comparison was useful to you. If you need any help setting up a workstation for Deep Learning, or you need hardware for an upcoming project, get in touch to find out how we can help.